Projects and Architecture
Building...
Spring 2024 |
Building...
Spring 2024 |
~% cd home
Projects and Architecture
A better way to fine-tune LLMs on consumer-grade hardware.
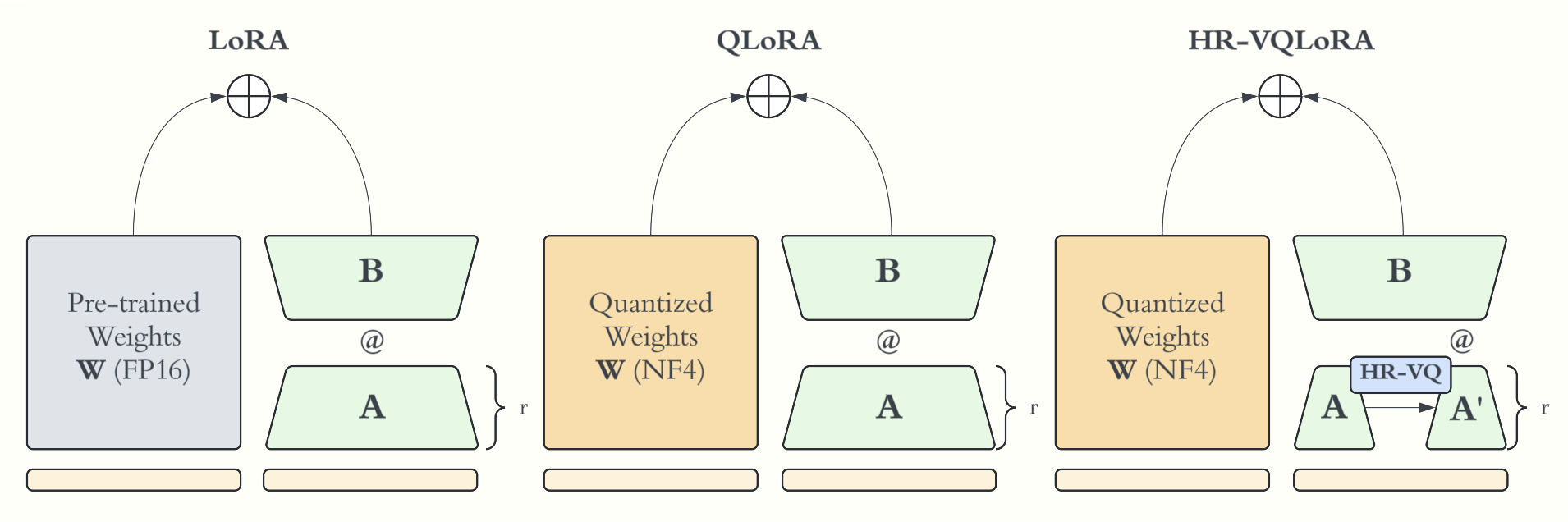 Quantize LLMs from 32-bit to 4-bit
Quantize LLMs from 32-bit to 4-bit
+ Training a low-rank (small) ΔW matrix
+ Adding a hierarchical adaptor
+ Including a custom loss function
+ Integrating into HuggingFace PEFT and Transformers
= One line integrations
= 8% better performance on MMLU
Read More.
Combining similar clips from your favorite podcasts with AI
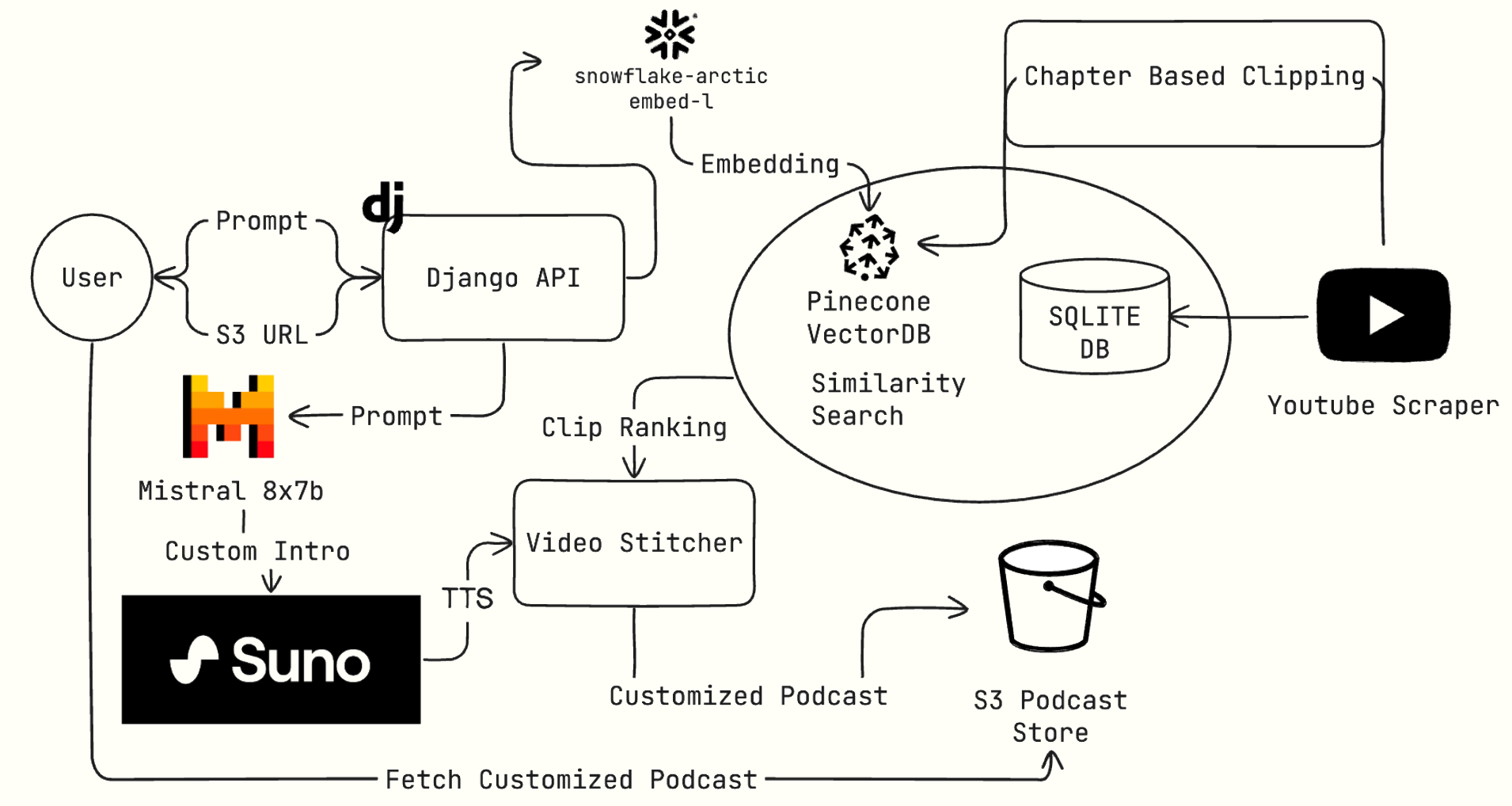 HackDartmouth 2024 Runner Up
HackDartmouth 2024 Runner Up
Read More.
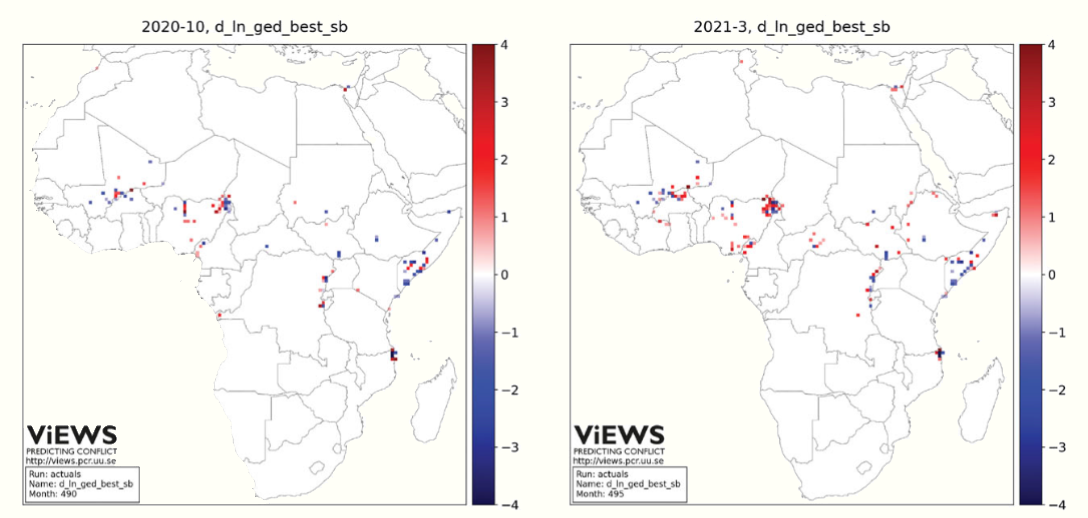
SOTA conflict forcasting at a subnational level using the Transformer
Winter 2024 |
Lorem ipsum dolor sit amet.
Spring 2023 |
A whitepaper on explainable AI.

Spring 2021 |
an offline game to play when camping with 77k+ downloads