HR-VQLoRA
quantized hierarchical residual learning of low rank adaptors
May 13, 2024 |
An Introduction
Without QLoRA
 With QLoRA
With QLoRA
How may we allow prosumers to train and finetune their own
Mult-Billion parameter neural networks?
How do we accelerate the deployment of AI on edge devices?
How can we democratize AI research and development?
What we did
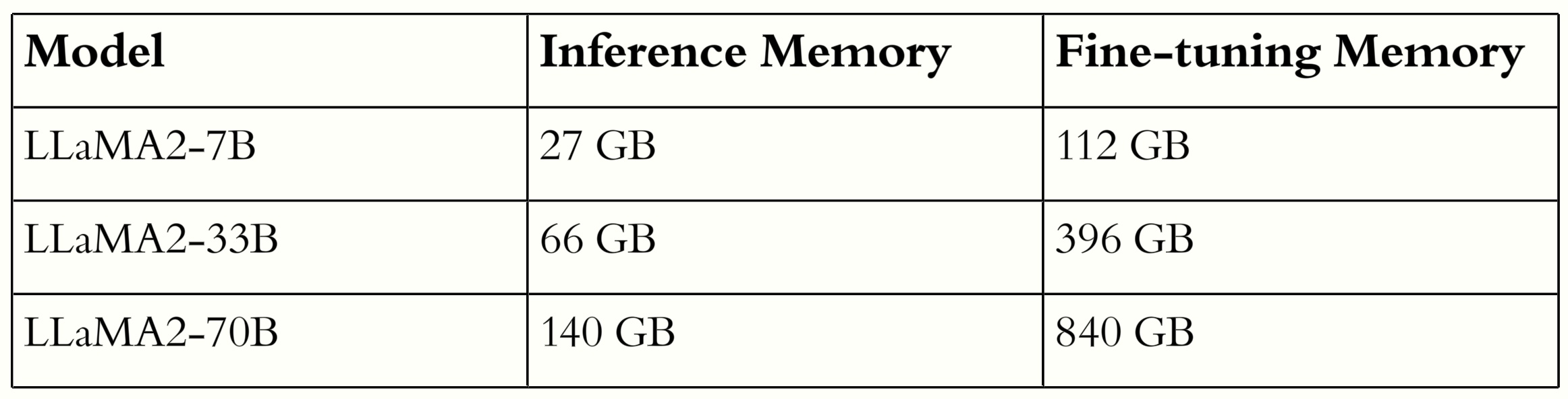
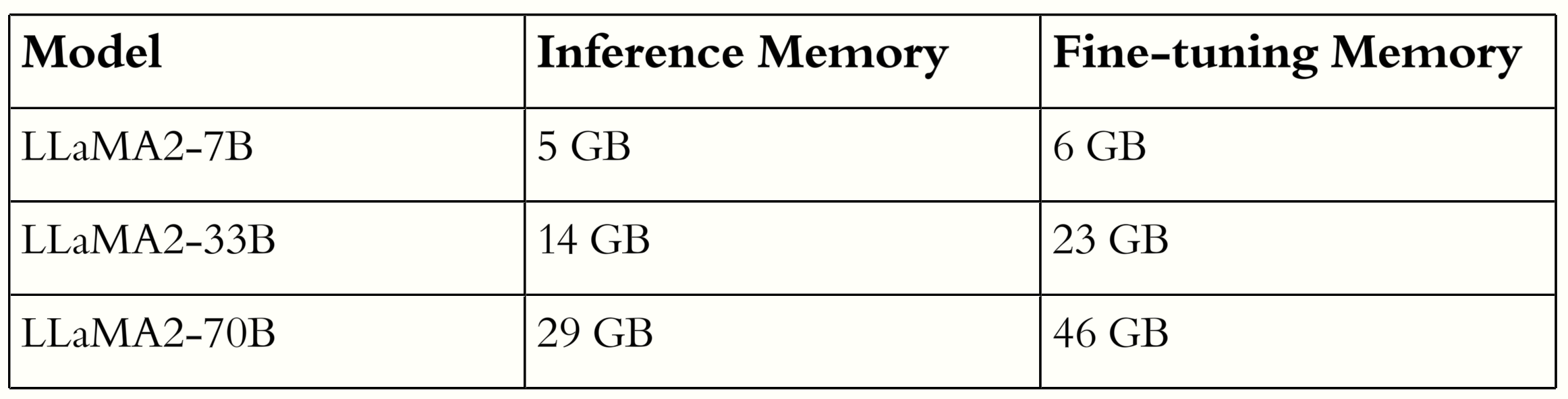
We allow finetuning The process of re-training a base-model like Mistral7B for a new task. of 7-33B LLMs natively on consumer-grade hardware.
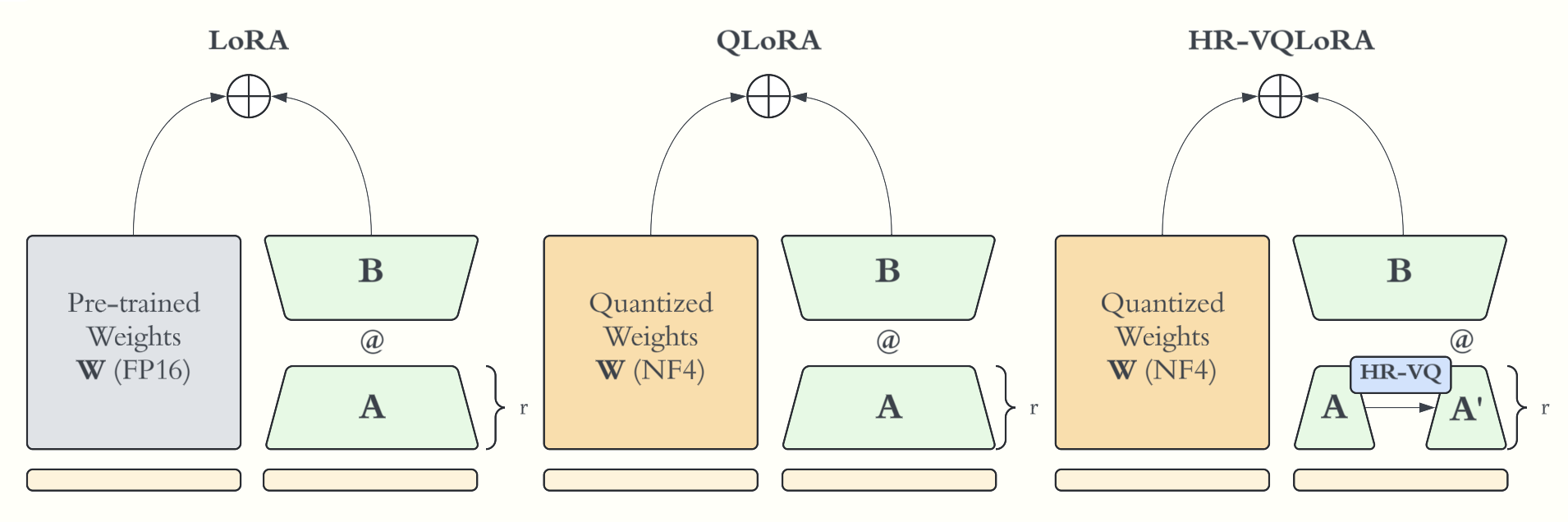
Our method recovers high resolution data that is usually lost in low rank adaptors to achieve better fine-tuning performance.
A hierarchical codebook learns a multi-level data representation using a novel loss function.
Jump to our results here We improve performance by 8.5% over SOTA QLoRA MMLU 5-shot accuracy on LLaMA-7B with no additional memory or compute costs at inference time.
We integrate our method into Huggingface's source code in Transformers and PEFT so anyone can plug and play.
Abstract
The fine-tuning of large language models (LLMs) in resource-constrained environments poses significant challenges due to their substantial size and computational demands. Previous methods have used substantial weight quantization to reduce the memory and computation costs of models at the cost of performance. In this paper, we introduce a novel method to learn hierarchical discrete representations of the low-rank weight delta, HR-VQLoRA. We implement a novel objective function to hierarchically link layers of a vector quantization codebook. Each layer learns a discrete representation of the residual from previous layers and encodes disctinct resolution quality. To evaluate our method, we fine-tune the LLaMA2 family of models and validate it's effectiveness over multiple instruction datasets and downstream tasks. We find HR-VQLoRA improves performance beyond state-of-the-art QLoRA on MMLU 5-shot by 8.5% on the OASST1 dataset, but also has no impact on inference costs or memory demands.
Results
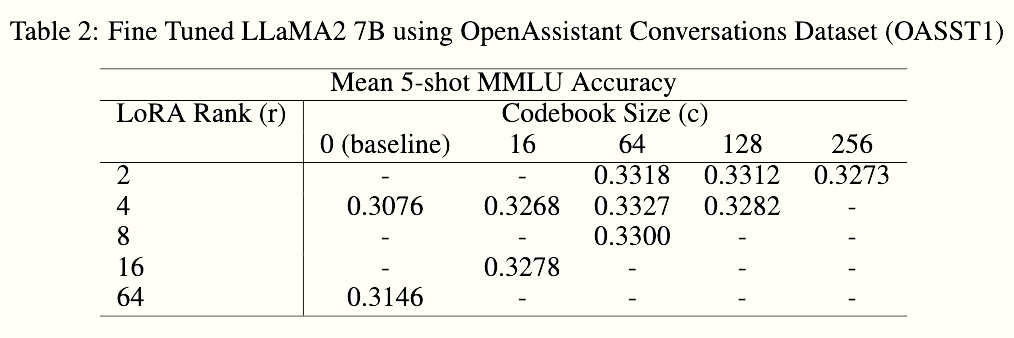
More currently training...